News
Anthropic Details Cyber Threat Classification System for Claude Fable 5
Anthropic has published details of the safeguards protecting Claude Fable 5 from cybersecurity misuse, along with a new scale for rating jailbreak severity developed jointly with Amazon, Microsoft and Google under Project Glasswing.
Contents
Anthropic has described in detail how it defends its newest model, Claude Fable 5, against being used for hacking attacks, and has proposed an industry standard for measuring how dangerous a given jailbreak is. It is the company's first publication of this kind with this level of detail, arriving as governments increasingly push for tighter control over access to the most powerful AI models.
Four Risk Levels
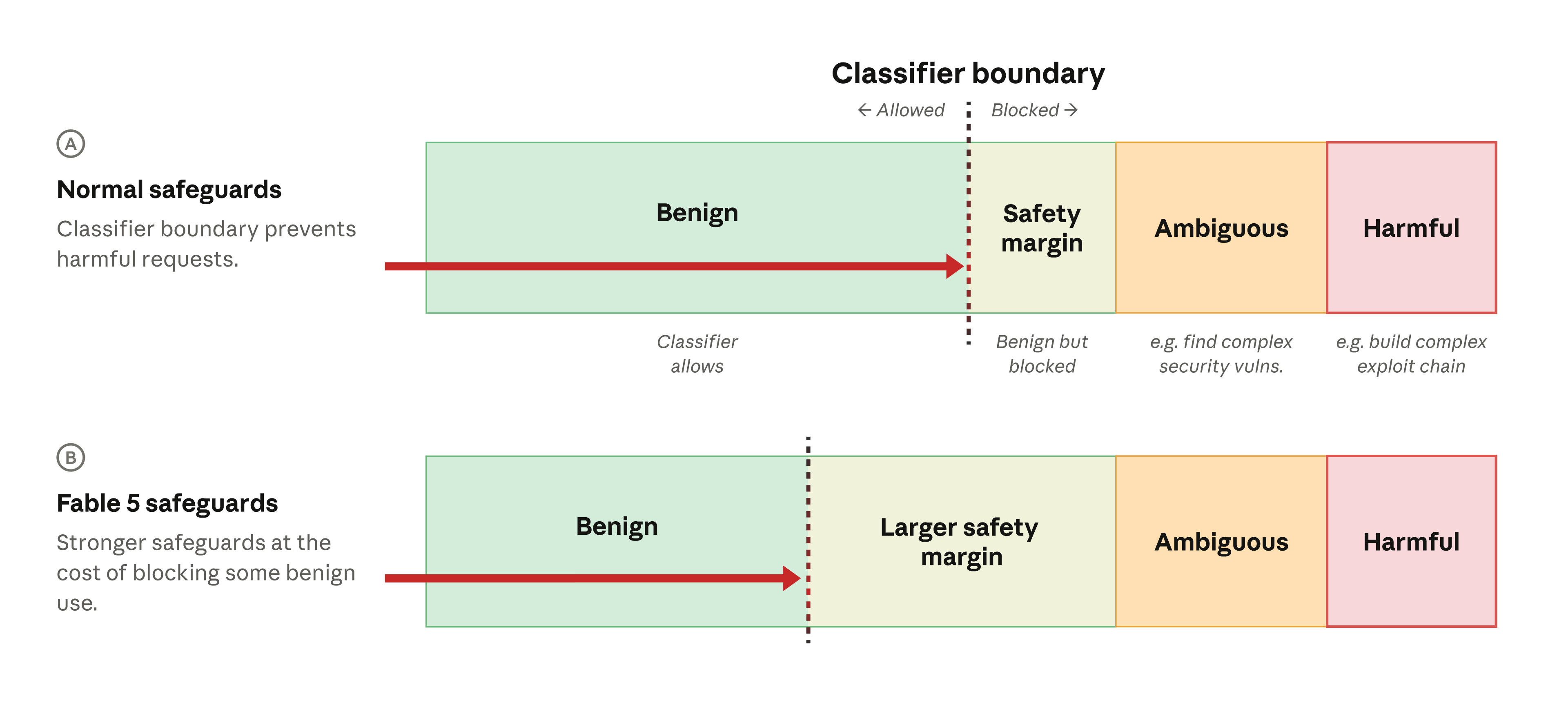
The classifier system in Fable 5 doesn't block all security-related activity; instead, it sorts queries into four categories. The lowest tier covers actions that are banned outright, such as creating ransomware or wipers, cyber-physical sabotage, or command-and-control infrastructure, since their potential for harm is high and their defensive value is low. Above that sit high-risk dual-use applications, such as penetration testing, exploit development or privilege escalation, which are blocked until a user's credentials can be better verified.
The third category covers low-risk dual-use activity, which is monitored but sometimes allowed, while the fourth covers benign applications such as secure coding, patch management, analysis in security operations centers, or incident response. Anthropic notes that the safety margin for Fable 5 has been set higher than for other models, meaning more harmless queries may end up blocked at the cost of user convenience.
The CJS Scale Explained
The new Cyber Jailbreak Severity scale rates how serious a given method of bypassing the model's safeguards is. The system tallies four indicators: capability uplift on a scale of 0 to 4, scope of application from 0 to 2, ease of weaponization from 0 to 2, and detectability from 0 to 2. The results combine into one of five levels, ranging from CJS-0 through informational and low, up to medium, high, and critical CJS-4.
The model follows logarithmic logic, so each successive level represents a substantially more serious threat than the one before it, rather than a linear increase. The final score can be raised based on additional discretionary factors, but never lowered, which is meant to prevent real threats from being downplayed.
A Shared Language for Industry and Governments
Anthropic is developing the framework together with Amazon, Microsoft and Google under Project Glasswing. The company describes this as an early step toward building a shared vocabulary between AI developers and governments, so that discussions of jailbreak risk look similar no matter which lab is reporting an incident. Comments on the proposal can be submitted to cyber-safeguards@anthropic.com.
By working together, we can establish a standard that enables defensive uses of this technology while preventing its misuse - Anthropic
The company has also launched a dedicated program on the HackerOne platform, where security researchers can report methods they've discovered for bypassing Fable 5's safeguards for review by Anthropic's team. This builds on the company's earlier experience with the Mythos model, whose access was restricted over the risk of cybersecurity misuse.
Regulatory Context
The publication comes just days after the US Department of Commerce lifted temporary export restrictions on Fable 5, which had been imposed earlier after a security vulnerability was discovered in the model. Fable 5 returned to all users worldwide on July 1, 2026. Government oversight of access to the most powerful AI models is growing in the US alongside the development of such industry self-regulation mechanisms.
For companies using Claude in cybersecurity, including Polish SOC (security operations center) teams or red-teaming departments, this means clearer rules of the game: legitimate penetration testing or fuzzing remains available after context verification, and the line between defensive and offensive work becomes the subject of an explicitly documented policy rather than a classifier's black box.
The CJS scale, if adopted more broadly by other labs, could become a reference point similar to the CVSS scales familiar from traditional vulnerability management, but for risks tied to bypassing the safeguards of language models. This also matters for regulatory bodies seeking a common language for evaluating reports on AI-related incidents.
Sources: More details on Fable 5's cyber safeguards and our jailbreak framework (anthropic.com), Anthropic Details Claude Fable 5 Cybersecurity Safeguards and Jailbreak Framework (cybersecuritynews.com)